本文最后更新于1 年前,文中所描述的信息可能已发生改变。
前言
记录了一些自己用过的AI相关的经验,较为浅显,仅供学习参考。
只是为了水博客而水罢了,因此不涉及训练模型,想到什么写什么,后面再补充吧。
AI生成文本
比较常见的有以下几个:
openAI ChatGPT
Claude
Copilot
Google Gemini
阿里巴巴 通义千问
百度 文心一言
智谱 智谱清言
以下是我用来测试的问题:
1.讲讲ChatGPT、Claude、Copilot、Gemini、通义千问、文心一言、智谱清言的区别与优劣。
主要检查收集信息有无错误或者纰漏
2. 一个人站在岔道口,分别通向A国和B国,这两个国家的人非常奇怪,A国的人总是说实话,B国的人总是说谎话。路口站着一个A国人和一个B国人:甲和乙,但是不知道他们真正的身份,现在那个人要去B国,但不知道应该走哪条路,需要问这两个人。只许问一句。他是怎么判断该走那条路的?
主要检查一下逻辑推理能力,不过这玩意有什么用?(如果甲是A国人,说的是真话,问甲:“如果我问乙哪条路是安全之路,他会指哪条路?”他指出的乙说的路就是错误的,另一条路就是正确的。如果甲是B国人,说的是假话同样的问题问甲,因为乙说真话,甲会和乙的答案相反,那么另一条路就是正确的。)
3.用python写贪吃蛇游戏
4.修改上述代码
5.(上传一张股票市场图片)请分析这张图片的内容并给出决策
6.(上传一个文档)请总结这篇文章的内容,并生成摘要
7.生成一张穿着白色衬衫的眼镜中年男性的图片ChatGPT
最开始使用的就是openAI家的ChatGPT,当时还是3.5版本,后来升级到4.0就要收费了,唉资本。这里试用一下gpt-4o,但我不打算充钱所以不会有太深入的研究。如果你不想注册账号,也可以尝试在Poe这个网站上面体验。
gpt-4o能通过我用的所有测试,但是不能生成图片,输入的股票市场图,给的投资决策也很正确。
太完美了,什么时候能免费啊。
但目前它一天允许的次数太少,巧妇难为无米之炊。
Claude
用的Claude 3 Haiku版本
上来第一个问题就回答出错,我没想到不是国产的也能回答错误这么简单的问题,没有检索到通义千问是阿里巴巴的。
股票决策也没给,图片也生成不了。
感觉没有吹得那么厉害…也许是我不怎么编程吧。
Copilot
现在在win11里内置的AI,由微软提供,edge浏览器里也有提供扩展(Ctrl + Shift + .),但是需要科学上网才能打开,我平时用这个也勉强够用了。
利用edge浏览器的扩展可以实现读取本地pdf文档,相比于其他的大模型需要上传来说方便很多,也方便去选取某段进行翻译或者精确定位让AI修改。
在代码方面和图片生成、文档理解方面表现还行,但图片理解、逻辑能力不行,令人感慨真是老东西跟不上时代
Gemini
由谷歌推出的大模型,一眼看上去UI设计很惊喜。
扩展方面有谷歌地图和油管,可以在直接搜油管上的相关视频,感觉是个特点。

因为政治正确目前没有图片生成,我也没找到文档上传的地方。
但至少显示出来的图片理解、逻辑分析(中英文)、代码能力等方面都非常好,还为我的输入的股票市场图提供了策略,回答甚至还会生成表格给我更直观的表示,挺不错的。
通义千问
扩展提供了实时语音转文字和字幕功能
显示出来的图片理解、逻辑分析、代码能力等方面等还行,但是你把文字转成英文就会出问题。国产大模型的水平都差不太多,感觉主要就是看有什么额外功能和价格吧。所以最近国产模型降价特别猛。
文心一言
没什么好的扩展
国产大模型的水平都差不太多,感觉主要就是看有什么额外功能和价格吧
智谱清言
清华大学那个模型后面改的。
扩展方面这个数据分析也许有用。
国产大模型的水平都差不太多,但他在图片分析时同样给了我策略,这点还是很不错的。
AI生成图片
AI绘画的网站真的是国内国外到处都有,随便找找就能找到,当然如果你有闲情雅致也可以自己训练。这几个是可以用的网站(建议不要氪金,因为更新实在太快了,很可能你充了钱之后这个网站就倒闭了):
LiblibAI·哩布哩布AI - 中国领先的AI创作平台
吐司(这个网站免费用户采样步数只有25,流汗黄豆了)
Civitai(主要是用来下载社区模型自己炼丹)
TensorArt
进入网站,选择合适的大模型和lora模型,然后在它们的基础上进行生成。lora模型和controlNet差不多和prompt(关键词)作用相似,都是为了更精确的描述/限制你想生成的图片(提高泛化能力)。
看不懂工作流怎么用qaq,这里先空着不写吧
web-ui的输入部分以下部分构成:prompt(关键词) 和参数设置。prompt分为正面tag和反面tag。参数设置基本包括采样方式Sampler(AI生成图像的方式。 影响图像质量和生成速度)、采样步数steps(迭代次数,适当提高可以改善画面效果,但也会增加生成时长)、关键词关联性cfg(控制生成图片与提示词的接近程度)。当然你也可以用图生图(将已有图片作为输入)继续生成。
可以直接使用别人已经写好的prompt和参数设置,例如:元素法典——Novel AI 元素魔法全收录|Chinese CoQ Production Committee,里面有很多prompt,你也可以根据元素同典:确实不完全科学的魔导书|Chinese CoQ Production Committee自己写prompt。关于prompt也可以用chatgpt尝试生成(最好用高版本的,如gpt4)。

这张图也是用元素法典里的prompt生成的,一眼就看到左手手指还有阴影有缺陷,但我懒得再炼了。
你会发现生成的图片AI感很强,或者是手指头发光影等有问题(这个采样步数拉高也许可以解决)。你看到的那些AI生成图片都是在调教好的prompt和参数设置下不断生成的无数张中选出来的相对正常好看的一两张,而且每张生成的时长长短也根据参数和显卡算力而不同,所以说这玩意嗯跑没个好显卡吃不消。
前几天看到NovelAI 3.0(收费)跑出来的二次元图一眼看上去已经完全看不出来生成的痕迹了,吃了钱之后的模型训练还是比社区好太多,当然社区的pony模型也很好看,而且手部方面崩坏少了。
AI生成视频
视频是由一个个图片帧连续播放形成的,既然能够生成图片,那自然可以生成视频。你应该在B站上刷到过动画角色AI跳舞的视频,具体原理可以参考:
15分钟入门AI动画!Mov2Mov零基础教学,用Stable Diffusion生成酷炫逐帧重绘动画短视频,开启低成本动画时代 | 扩展插件教程_哔哩哔哩_bilibili
AI视频时代的“开源先驱”:Sora来之前,你可以先掌握这些——AnimateDiff动画插件全方位教学,制作丝滑流畅动图!Stable Diffusion应用_哔哩哔哩_bilibili
当然一段时间后就很少看见这类视频了,大家似乎对这种三渲二视频不太感兴趣。这也侧面说明了AI生成视频也是卷得飞起,这些网站几乎都是在被完爆之后才免费的,那么Runway什么时候爆金币呢?
以下是一些可以生成视频的网站:
文或图生视频
sora(这玩意还没公测,之后再补链接吧)
Stable Video Diffusion(一个开源模型,之后看看有没有云端部署,先空着吧)
Runway
Pika
Genmo
PixVerse(不推荐)
即梦Dreamina(国产的)图片内角色跳舞
AI换脸
这里放一些提示词网页:
Danbooru标签
MidJourney关键词 (你可以在它的readme.md找到想要的)
Runway
Runway需要科学上网,注册后会提供100秒的免费生成时长,而它一个视频是4s,基本够练练手。它主要可以文生视频和图生视频。
如图所示,左边的图标分别为
prompt(关键词,一般是文字描述或者图片,如果仅使用文字请尽量描述长一点,它也提供了一个灯泡按钮帮你一键扩写)
general settings(一些参数设置,包括画质、负面tag、cfg权重控制ai自由度、种子数字以及会员才能用的去水印)
camera settings(摄像机移动,可以上下左右甚至倾斜摄像机以达到不同效果,大概和ae里的摄像机类似)
motion brush(运动笔刷,可以用笔刷指定某一区域的上下左右前后运动,妈妈再也不用担心我抠图K关键帧做头发动作做到猝死辣)
custom model(使用自己训练的模型,收费的,略过)
style(一些预设的风格模型,免费的,你也可以不选,和lora模型与大模型的关系类似吧)
aspect ratio(分辨率)
custom presets(你自己保存的预设选项,包括prompt文字描述和镜头移动这些)
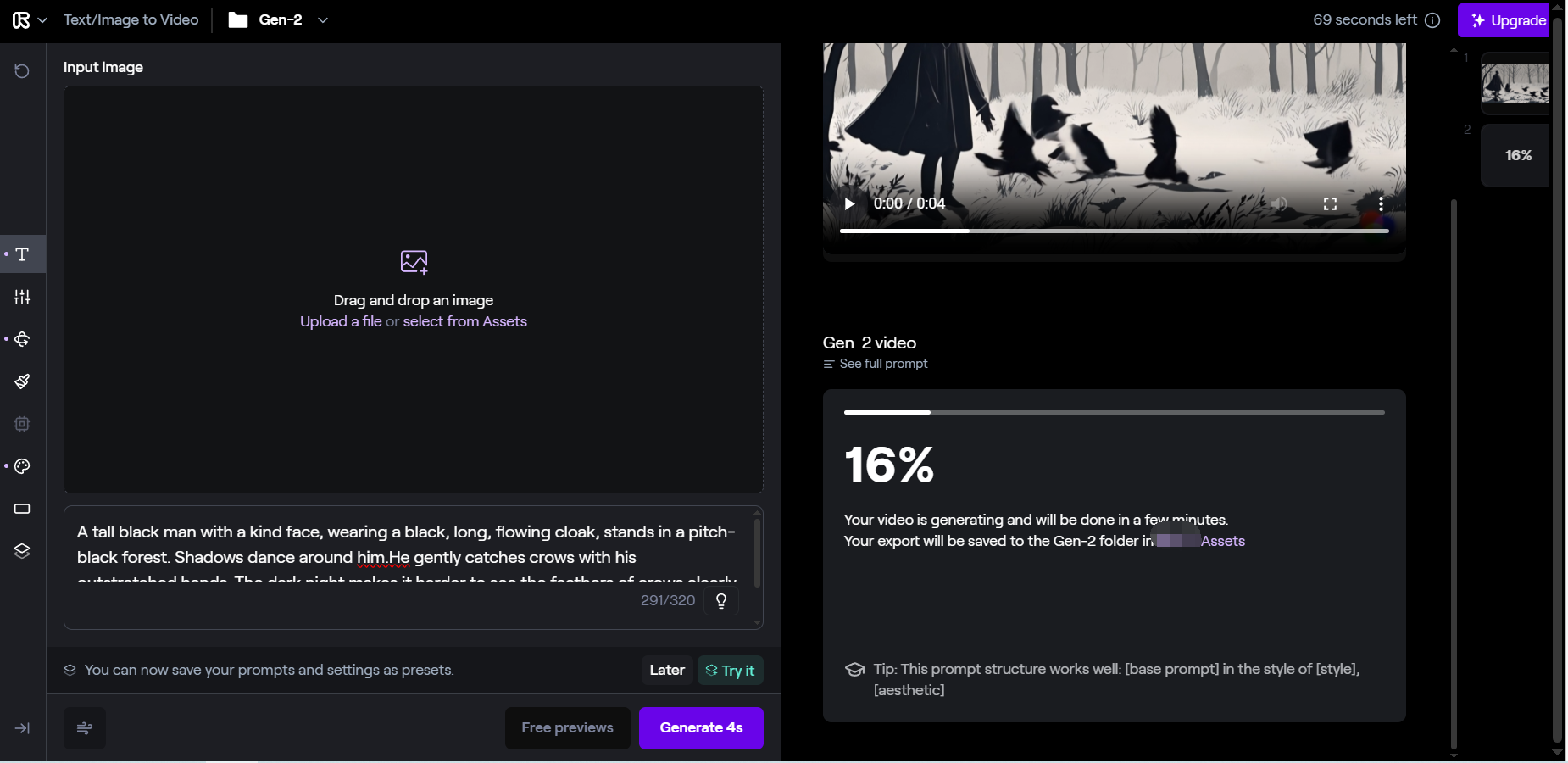
自己测试了一下,感觉文生视频不太好用(难道是“一个黑人在黑夜里捉乌鸦”太刁钻了?),生成的人物经常不动。主观使用上我认为这个网站更多的还是用图和文字prompt一块输入生成。
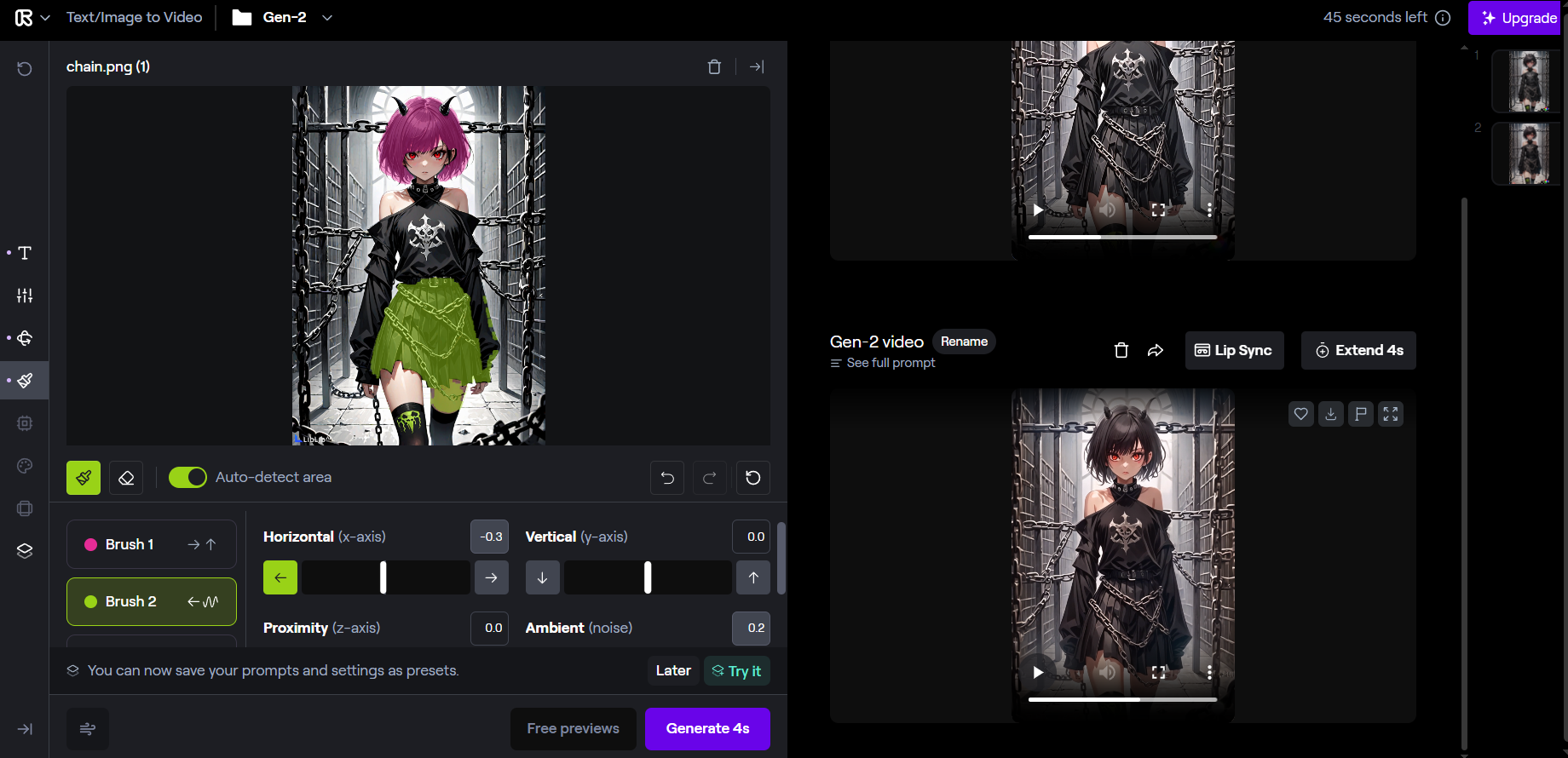
投喂二次元图的效果挺不错,会自己补光影,头发飘动也能自己调,虽然裙子摆动调不出来而且眼睛看上去很糊,但是看上去没有太大的崩坏。
Pika
Pika需要科学上网,注册后貌似Pika 1.0是免费。 这个网页提供了视频内音效生成(虽然比较构思)。参数里主要是摄像机控制(没有抠图笔刷差评),分辨率,负面tag和帧率、动作强度、cfg权重控制ai自由度。做完之后还能一键重做或者重编辑prompt,很好用。
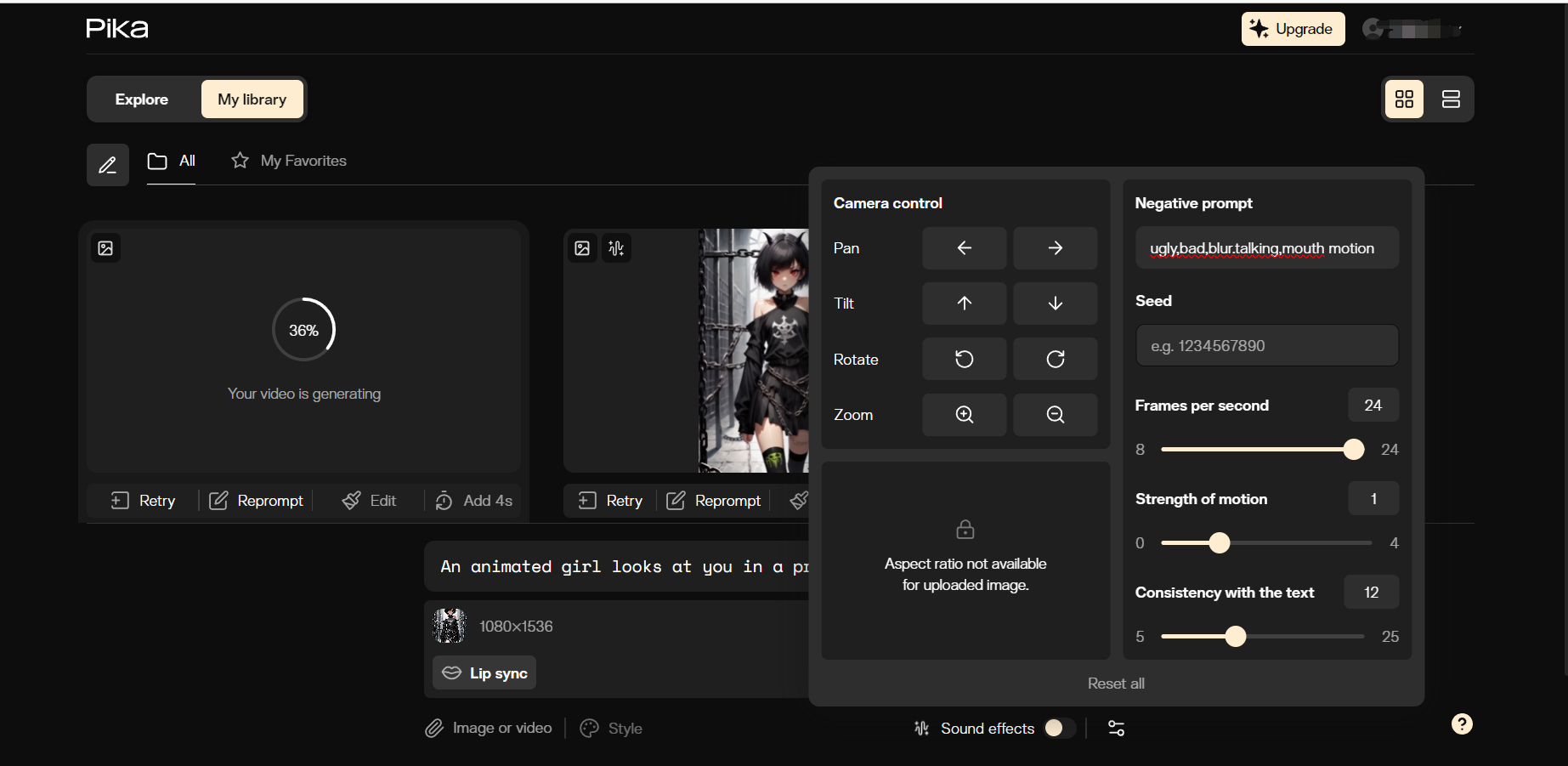
投喂二次元图生成的效果还行,但是越到后面画面越糊,负面tag修饰也救不了,猜想是不是快门速度的关系,懒得找了。它都不限时长了what can I say?包好评的。
Genmo
需要科学上网,注册后免费。 除了图文prompt外,提供了摄像机运动和滤镜,但摄像机运动只有缩放和旋转令人发笑。
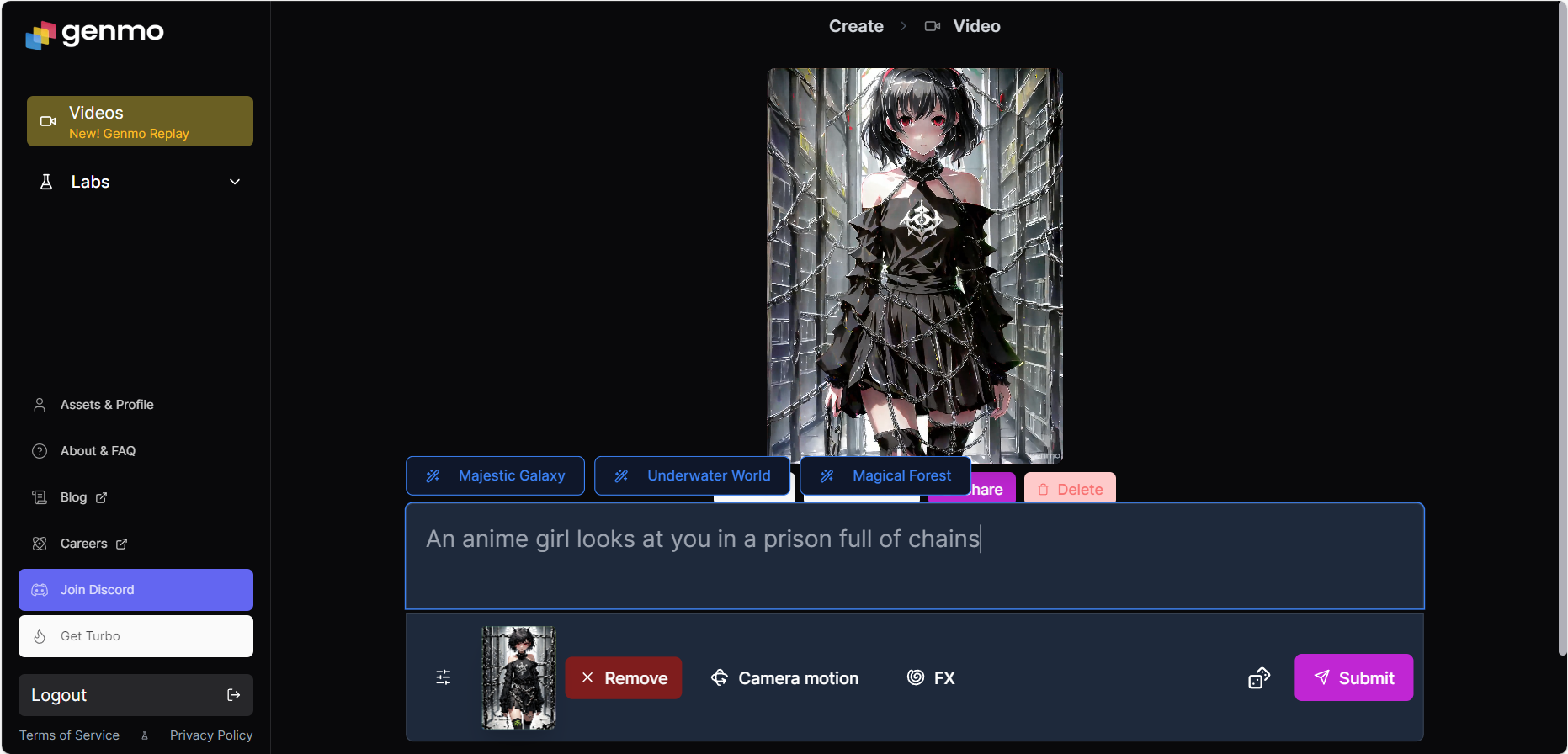
投喂二次元图生成的效果是依托答辩,但是它做出来一个裙摆下落的动作令我感到惊讶,之前的网页是做不出来这个的,它能理解裙摆因为重力下落?也许换成真实图片会有不错的表现。
在这里贴一个大佬做的比较视频:AI视频生成效果比较:pika/genmo/runway_哔哩哔哩 | 蛙仔AI,懒得自己再投喂图了
PixVerse
需要科学上网,注册后有200额度,生成一次消耗10点。 图文生成方面没什么好说的,该有的摄像机运动之类的都有。值得一提的是它提供了按照角色进行生成的模式,也就是说你可以把自己喜欢的角色的几张图喂到里面再通过文字prompt进行生成,算是有新意吧,不过感觉不好用哈哈。
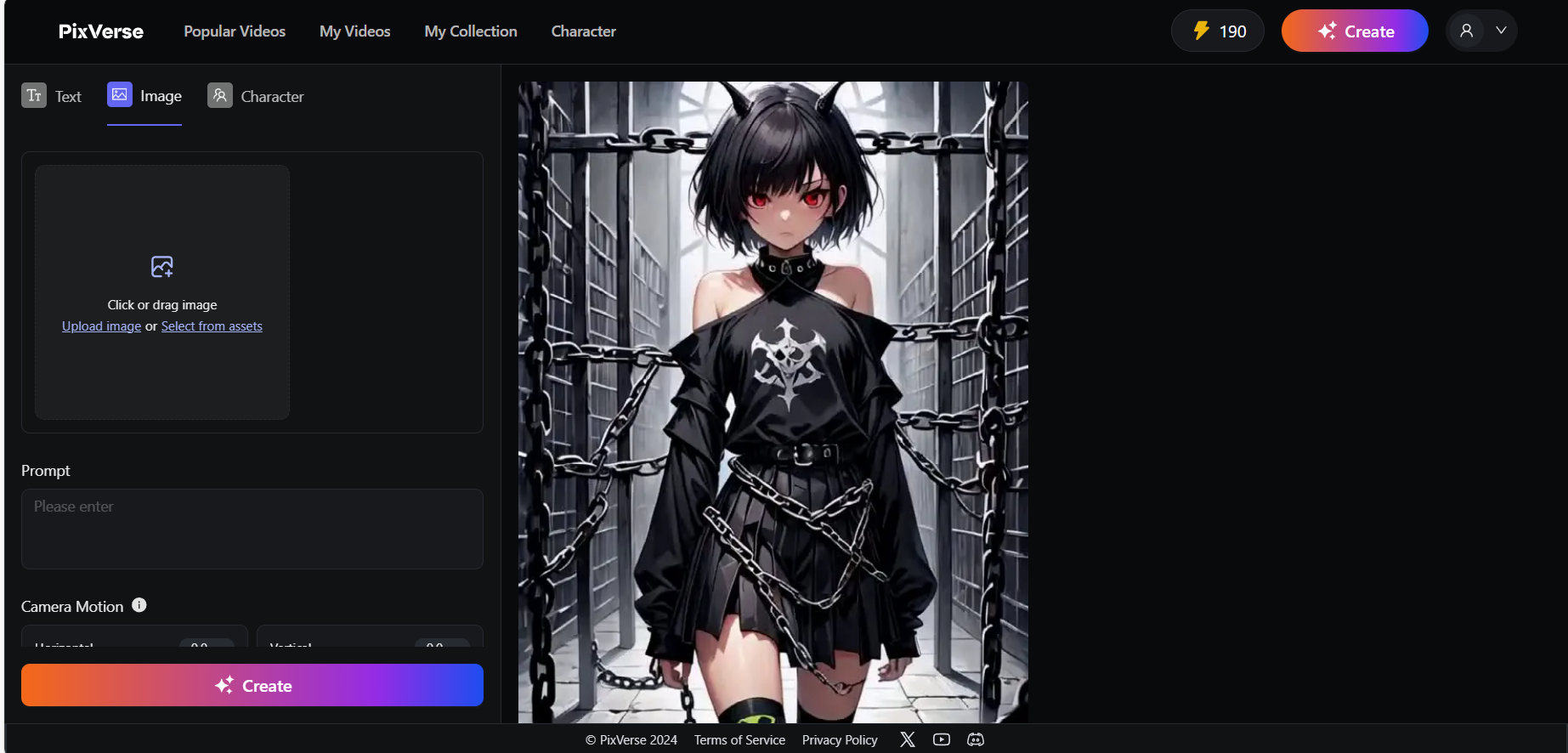
投喂二次元图生成的结果动作太少了,头发裙摆锁链都不动,仅仅是摄像机画面的缩放,所有网站prompt写的都是一样的,生成这样的效果只能说是被其他的完爆几条街了,再加上它还收费,很不推荐。
即梦Dreamina
国产的,B站有官方账号Dreamina的个人空间-Dreamina个人主页-哔哩哔哩视频 (bilibili.com),免费额度每天60点,但生成一次就要12点,贵死了。 prompt支持中文,摄像机运动比较少,参数设置也比较少。
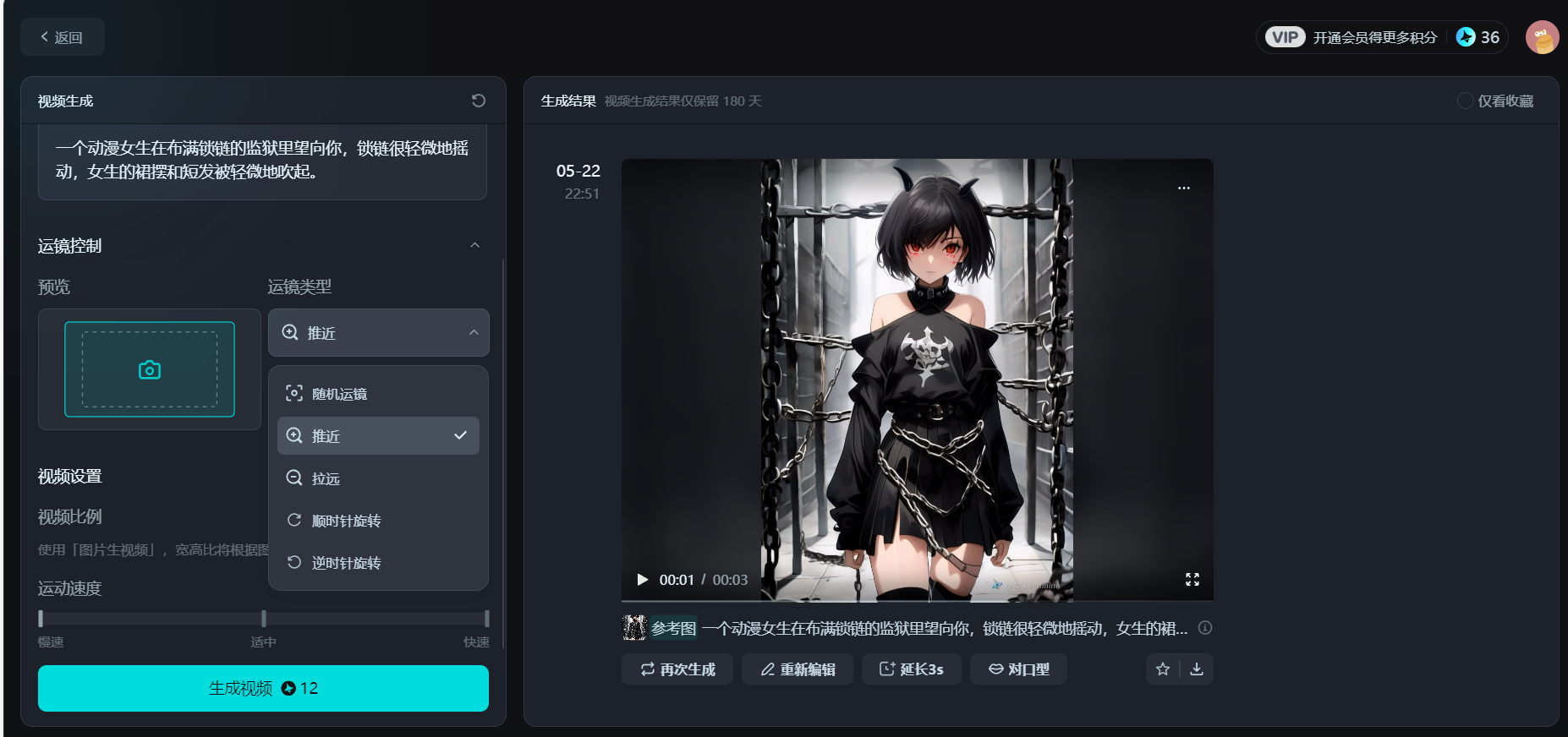
生成的结果我个人感觉该动的地方不该动的地方都在动,比起runway能控制运动区域来说个人认为欠佳,但是国产的能做到这样不错了,但是收费好贵。
Viggle
经常会看到一些视频里的角色突然就开始跳鸡你太美,好奇查了下。
参考:用AI让照片跳舞,制作动作模拟恶搞视频,Viggle使用方法 | 聪明小鱼鱼up
进到官网discord服务器之后,在左边选一个服务器animate服务器进去,最下面发送/mix然后上传文件,最后搜索自己的名字等一会就能找到了。 
效果其实挺一般的,但视频里那些也差不多,不想要绿幕可以自己上传背景,水印部分你自己把分辨率调大一点然后把水印截掉吧。
AI生成音频
语音
写到这里最先想到的是VITS,它可以依靠少量音频就可以训练出一个人的说话声音,可以用来配音。训练模型整合包几乎B站到处都是,难搞的是好的训练集。以下是一些模型demo的链接:
文生语音
Clipchamp(和微软Azure一样的但不用去绑定银行卡,在里面有文字转语音)
Fish-Speech在线推理Demo | fish.audio(有一些动漫手游角色的语音模型)语音生成语音(最好去掉背景声,下文有提取人声的工具)
Sovits Teio(可以用来生成哈基米的声音,参考这个视频【sovits4.0模型分享】让AI帝宝/诗歌剧唱歌 | Saya睡大觉中)
如果你仅仅是需要给你的视频配音,那微软的Azure就已经足够你使用了,市面上很多营销号的AI配音就是这个。
但毕竟Azure只提供了一些微软官方请的声优声源,如果你想要别的自定义声源,目前主要有GPT-sovits,Bert-visits和Fish-speech三种模型,按照顺序越往后的性能越好,前面的估计要被淘汰了。我只放了Fish-speech的demo,如果想体验一下老的GPT-sovits和Bert-visits的模型可以B站关注Xz乔希 | bilibili然后私信自动回复的链接有一些他训练过模型的demo。
语音生成语音这方面主要有三个模型:RVC、DDSP和sovits(现在是sovits 4.0)。RVC主要是用在实时声音转换,即AI变声器。DDSP相比于RVC实时转换,它转换的声音更加自然,相比于sovits它配置要求更低效果差得不多。sovits应该是目前转换效果最好的模型。
遗憾的是我找不到这三个的网页版,只能拿很早之前的sovits体验一下了,而且只能转换几秒钟,如果想AI翻唱看来还是得自己部署。
音乐
提取人声
音乐生成
说到音乐生成那就是Suno了吧,注册后一个账号一天可以生成10次(没次数了不想等可以重新注册),不氪金每首上限为2分钟。
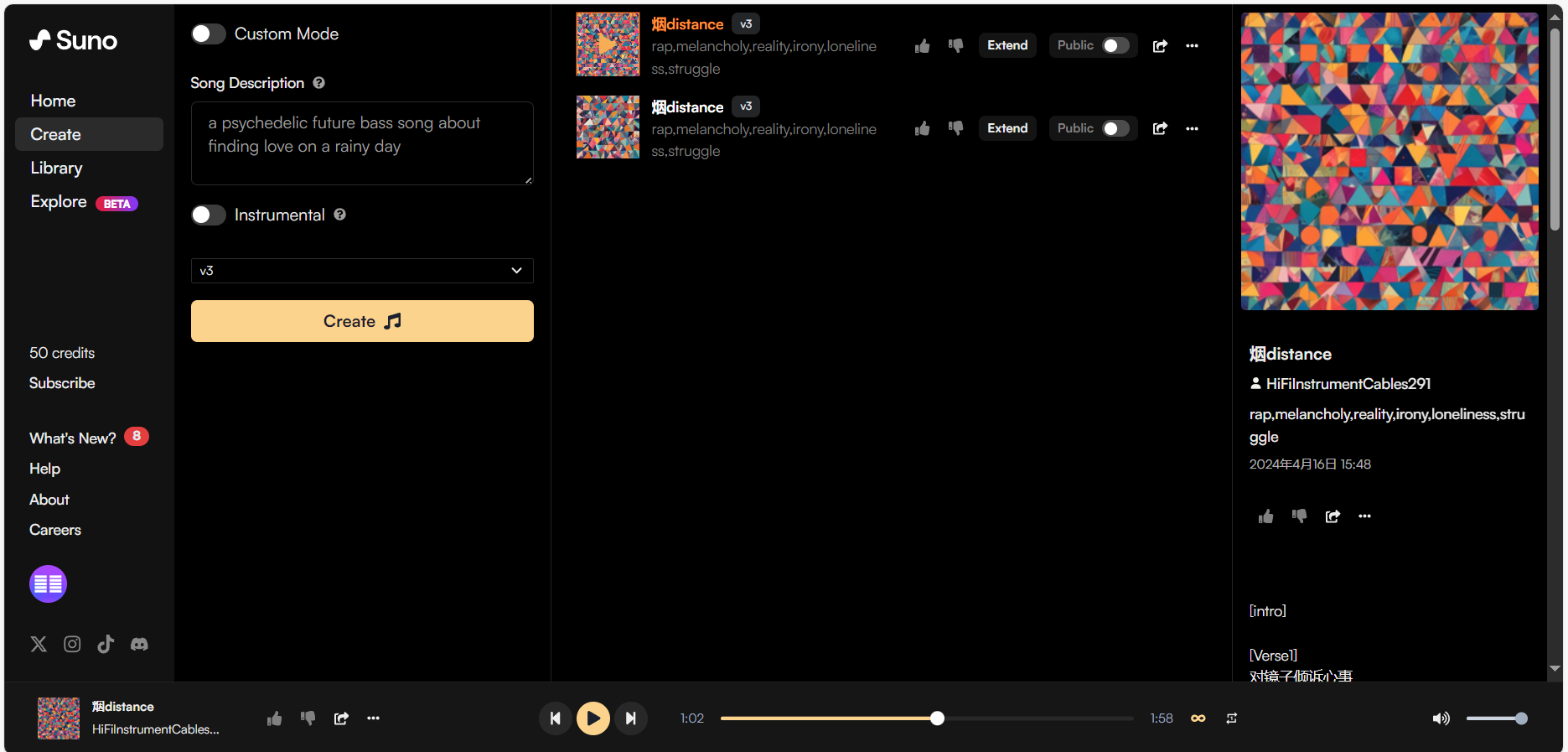
不打开自定义模式custom mode,你可以通过文字描述(当然你可以用AI生成描述)让AI自己选择歌词、风格、命名,勾选乐器Instrumental可以生成纯音乐。
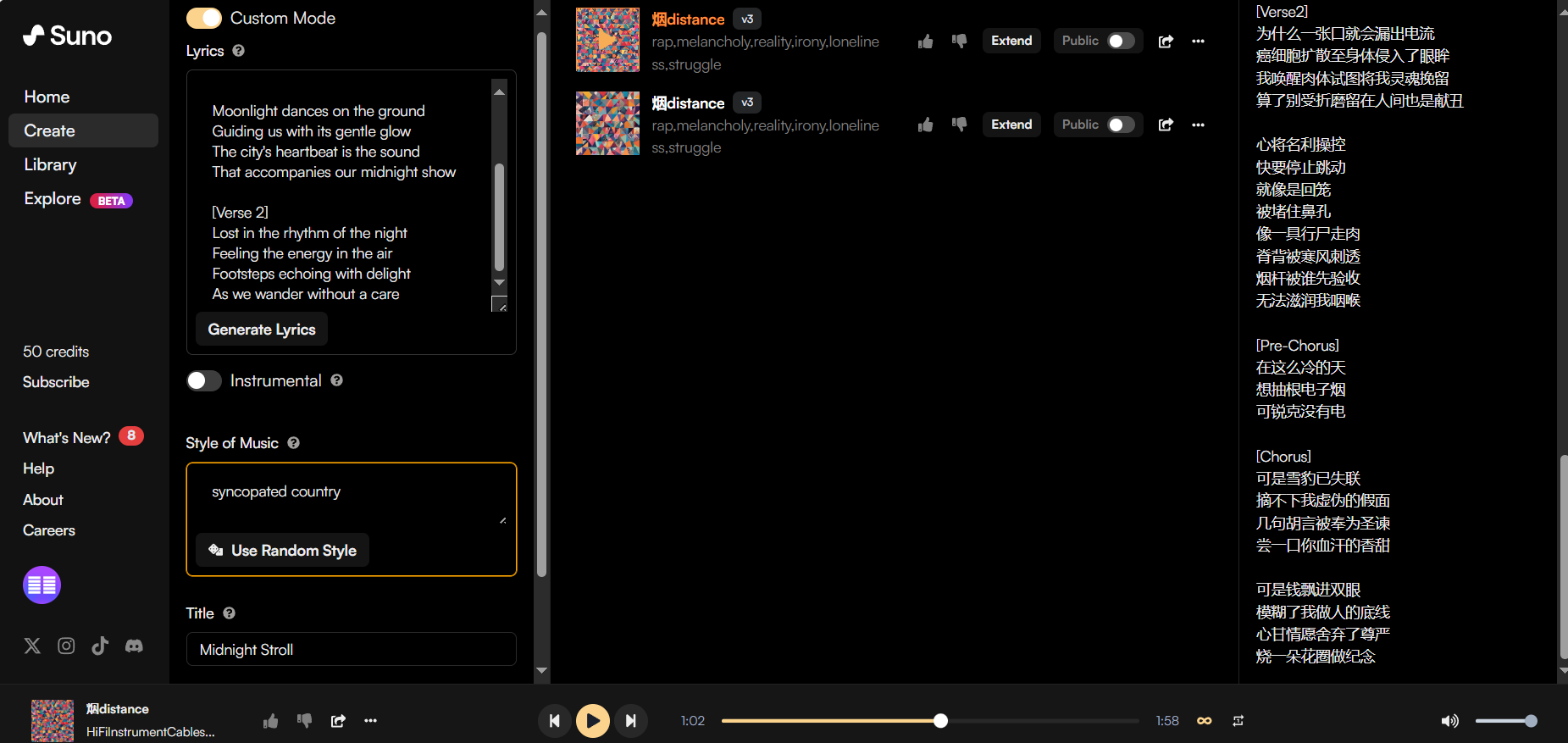
打开自定义模式后可以指定歌词和音乐风格并取名。值得一提的是,在歌词中你可以使用prompt(元标签metatag)为其指定主副歌段,甚至连演奏乐器和方式也可以指定。如果不用prompt直接塞烂梗作曲的话AI也会帮你自动划分的。
以下是一些参考文章:
歌曲结构 101:每个词曲作者都应该知道的基础知识 |Native Instruments 博客
Suno音乐新手指南(手把手完整版教程)| AI魔法学院
结语
从22年第一次用gpt开始到现在,AI可以说是飞速发展。资本提供了更好的数据集获得更好的AI模型,更好的模型反哺资本增长,资本下的模型逐渐拉大与社区间的差距。另一方面大数据模型的降价、本地部署配置要求降低也证明AI的使用门槛越来越低。但随之而来的伦理和法律问题也令人堪忧。
头一次体会到也许我们真的处在技术革命当中。